
지금 개인적으로 하려는 프로젝트도 크롤링 관련이기도하고 크롤링이 어떤식으로 동작하는지가 많이 궁금하였다.
아주 쉽다. 라이브러리를 잘 써주기만 하면 된다. 크롤링은 파이썬 라이브러리들이 가장 편하고 범용적이어서 파이썬을 쓰는게 가장 좋다고 한다. 나는 scrapy라는 라이브러리를 이용해서 github.com 페이지 중 하나를 간단히 크롤링해보았다.
Scrapy 설치
먼저 scrapy를 설치하기전 파이썬 버전을 확인해본다. scrapy는 파이썬버전 2.7부터 지원한다. 단 3.0 이상으로 올리면 안되는 기능이 있을지 모른다. scrapy를 설치하기전에 파이썬 관련 설치툴인 pip와 easy_install이 없다면 설치해주어야 한다. 또한 lxml도 없다면 같이 설치해준다.
>> pip install lxml
>> pip install scrapyscrapy가 제대로 설치되었는지 확인해본다.
>> scrapy --version프로젝트 만들기
다음 scrapy 프로젝트를 만들어본다. 장고처럼 명령어를 입력하만하면 기본적인 템플릿은 다 만들어준다.
scrapy startproject 프로젝트 명 프로젝트 명으로 폴더가 만들어지고 만든 폴더의 구조를 보면
- scrapy.cfg: 설정파일이 있다. 프로젝트 자체에 관한 설정이다. 예를들어 설정파일은 어디있고 프로젝트 파일명은 어떤것이고..
- 프로젝트 명/: 이 폴더에 프로젝트 관련 모듈이 들어간다. 일단 기본적으로 startproject 때 입력한 프로젝트 명으로 중복해서 폴더가 만들어진다. 설정파일에 보면 기본적으로 이 파일명으로 세팅이 되어있다.
- 프로젝트 명/items.py: item 즉 vo라고 생각하면 된다.
- 프로젝트 명/pipelines.py: 파이프라인 관련 파일이다. 파이프라인이란 scrapy의 item을 가지고 디비에 데이터를 집어 넣거나 유효성체크를 하거나 다른아이템들과 가공을 하는데 사용한다.
- 프로젝트 명/settings.py: 설정관련 파일이다.
- 프로젝트 명/spiders/: 크롤링 하고자 하는 코드들이 들어간다. 여기서는 스파이더라 부르는데 일종의 비지니스 로직이라고 생각하면 된다.
설치가 끝났으면 이제부터 간단히 깃헙의 이슈페이지를 크롤링해서 메일을 보내보자. 이번 포스팅해서는 간단히 크롤링만할것이기 때문에 아이템이나 파이프라인은 쓰지 않을 것이다. 좀 더 고급진 기능을 원한다면 아래 링크에 있는 scrapy 홈페이지에 자.세.히 나와있다.
크롤링은 spider폴더 내에 파일을 만들고 실행시킨다. DmozSpider파일을 만들고 입력한다.
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz" // crawling 작업의 이름
allowed_domains = ["dmoz.org"] // 사이트의 도메인
start_urls = [ // 크롤링할 페이지
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)위는 scrapy홈페이지에 나와 있는 소스코드이다. name은 작업의 이름, start_urls는 크롤링할 사이트들의 배열이다.
scrapy crawl name터미널에서 실행시키면 parse 함수가 실행되어서 해당 디렉토리에 크롤링한 파일이 만들어 질것이다.
인증처리하기
위의 예제는 링크만 치고 누구나 들어갈 수 있는 사이트이다. 그러나 github는 로그인이 필요한 서비스이다. 그래서 인증 절차를 거쳐야한다. 방법은 여러가지가 있다. 로그인하는 폼의 엘리먼트를 찾아서 값을 대입하는 방법, 세션값, 혹은 쿠기값을 변경하는 방법, form request를 보내는 방법등이 있을 것이다. scrapy는 scrapy.http를 이용해 이러한 처리들을 가능하게 해준다. 하지만 parse함수 전에 로그인하는 과정을 어떻게 시켜줘야 할까. 직접 구현할 필요는 없다. scrapy에 내장된 initspider라는 걸 상속받으면 parse를 오버라이드해서 parse실행전에 다른 작업들을 할 수 있게 해준다. 아래코드를 보자.
from scrapy.spider import BaseSpider
from scrapy.contrib.spiders import Rule
from scrapy.contrib.spiders.init import InitSpider
from scrapy.http import Request, FormRequest
class GithubSpider(InitSpider):
name = "github"
allowed_domains = ["github.com"]
login_page = "https://github.com/login"
start_urls = "https://github.com/vnthf/example/1"
rules = (
Rule(SgmlLinkExtractor(allow=r'-\w+.html$'),
callback='parse_item', follow=True),
)
def init_request(self):
return Request(url=self.login_page, callback=self.login)
def login(self, response):
return FormRequest.from_response(response,
formdata={'login': 'minho-choi', 'password': 'abcd'},
callback=self.check_login_response)
def check_login_response(self, response):
//check login success
if success
return self.initialized()
else
return self.error()
def initialized(self):
return Request(url=self.start_urls, callback=self.parse_item)
def parse_item(self, response):
//doing parse
Spider에서 InitSpider를 받는다. 크롤링을 시작하게 되면 initRequest 메소드가 가장 먼저 불린다. 여기서 로그인 할 페이지와 실행될 메소드를 지정해준다. login 메소드에서는 FormRequest를 이용해서 해당 페이지에서 submit요청을 보내도록 한다. 요청이 끝나면 check_login_response가 불리는데 여기서 로그인이 제대로 되었는지 확인하면 된다. response를 분석해 로그인 성공 여부를 판단한다. 여기서 response는 form request를 보내고 뜨는 페이지이다. 가장 쉬운 방법은 로그인해서 성공했을때의 페이지를 직접 보고 로그인에 성공했을 때 나타나는 엘리먼트가 있는지 보고 판단하는 것이다. 이 부분은 크롤링과 관계가 있어서 크롤링하는 방법은 바로 다음에서 살펴보도록 하자. 로그인이 제대로 되었다면 initialized에서 초기화 하고 parse_item이 불릴것이다. 이제 원하는 페이지에서 크롤링 할 수 있는 환경이 갖추어졌다.
크롤링하기
크롤링하는 방법은 정말 쉽다. 그저 html결과물인 response를 분석하고 해당 tag나 id, class명으로 Dom위치를 찾아다니는 것이다. scrapy에서는 xpath와 css문법을 지원해준다.
이슈페이지를 살펴보자
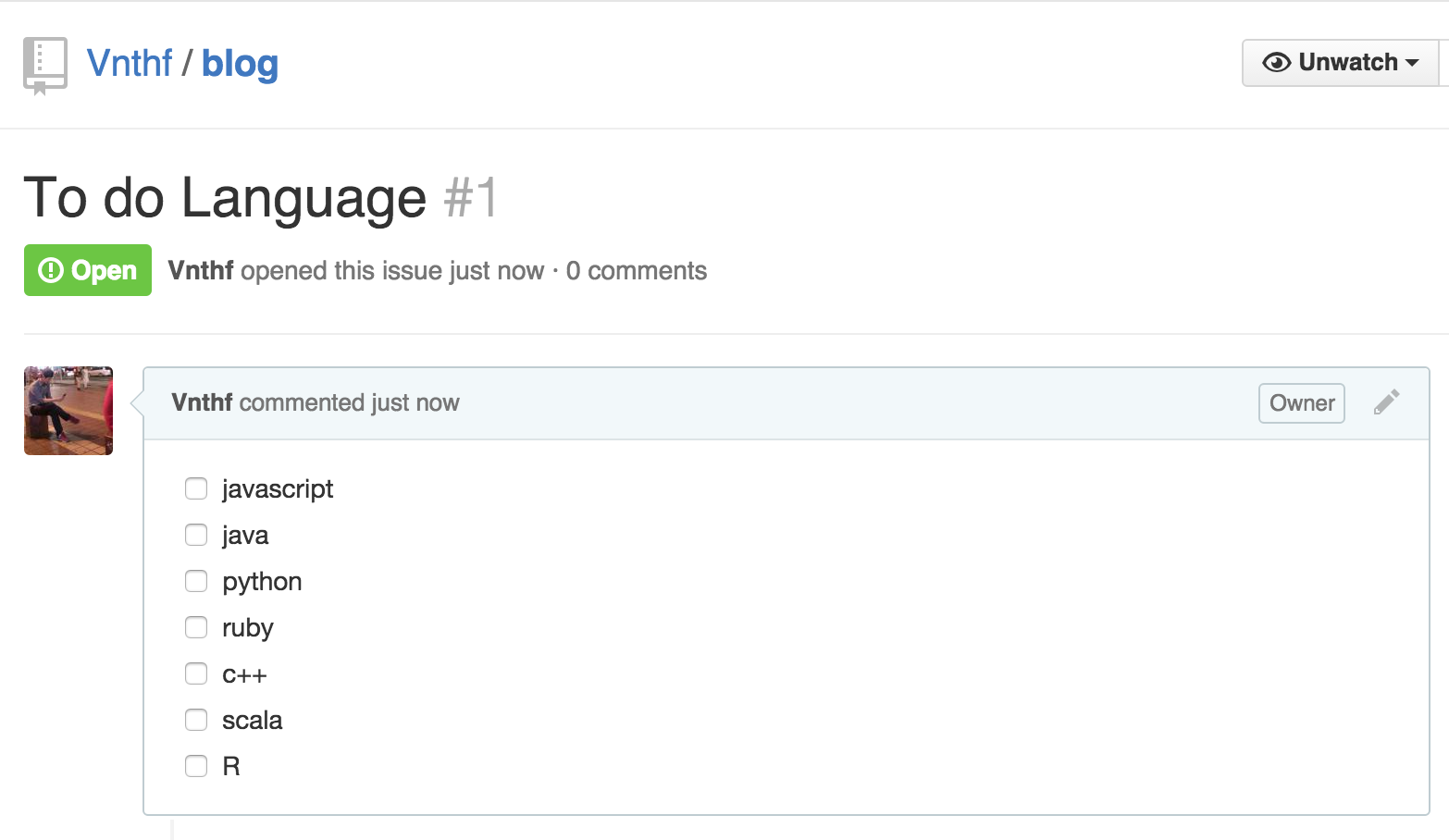
먼저 개발자 도구를 키고 이슈번호가 든 체크박스돔을 찾아야 한다. 여기서는 .task-list로 되어있다. 하위 돔인 .task-list-item을 찾아서 배열로 받으면 좀 더 가공하기 편할 것이다.
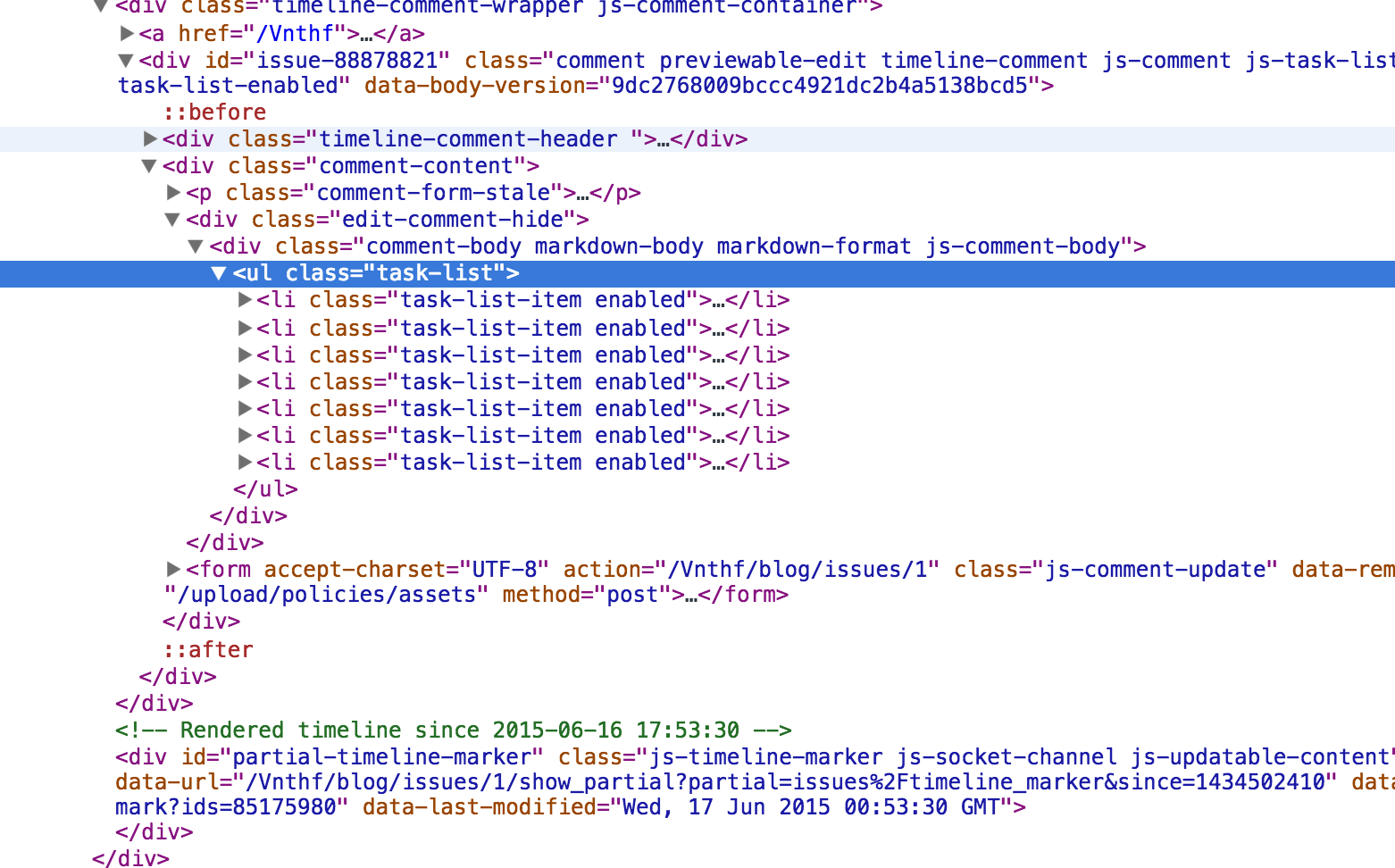
다음 scrapy.selector를 이용해서 scrapy가 지원하는 형식으로 response를 바꿔준다. 그러면 xpath 와 css를 이용해 원하는 정보를 찾을 수 있다. 둘 중 뭐를 선택하든 자유다. 문법에 관한 설명은 홈페이지 예제를 보면 된다. 나에게는 css문법이 훨씬 편해보였다. 아래는 간단한 예제이다. 이런식으로 정보를 얻어서 원하는 정보를 출력하거나 가공하거나 scrapy item을 이용해서 파싱할 수 도 있다.
from scrapy.selector import Selector
hxs = Selector(response)
members = hxs.css("li.task-list-item")
for index, member in enumerate(members):
isWrited = len(member.xpath('input/@checked').extract()) > 0 and True or False
text = member.extract()
name = re.split('>', text)[2].split('<')[0].strip()
print isWrited, name메일 보내기
메일은 scrapy.mail을 이용하면 쉽게 보내진다. 자세한건 홈페이지를 참조하면 되고 다만 메시지를 쓸 때는 MIME형식에 맞춰 쓸 수 있도록 관련 라이브러리를 MIMEMultipart, MIMEText와 같은 import에서 사용하기 바란다.
mailServer = smtplib.SMTP('smtp.gmail.com', 587)
mailServer.ehlo()
mailServer.starttls()
mailServer.ehlo()
mailServer.login(gmailUser, gmailPassword)
mailServer.sendmail(gmailUser, recipients, msg.as_string())
mailServer.close()- scrapy : http://doc.scrapy.org/en/latest/